Part 1: SQLDataSource FTW
About 10 years ago, I was working for a Fortune 500 company whose primary line-of-business application was built using a homegrown framework that was loosely based on a Java Model 2 / MVC type of architecture.
I’d been asked to come up with a way to migrate away from that platform in phases and was looking at alternatives. We liked the idea of GWT at the time, and like many people, I found SmartGWT while I was evaluating various widget libraries. Right away, we were impressed by the depth and breadth of what the components could do out of the box (ListGrid comes to mind), but we pretty quickly realized that the server framework is equally powerful, if not more so.
At the time, Hibernate was considered the obvious choice for your persistence strategy, and a lot of people still feel that way. With respect, I think I’ll just say that even proponents of Hibernate will ask you to invest in a pretty steep learning curve to understand how to use it properly, and then say that you’ll probably still have to write at least some (if not most) of your own SQL.
Frankly, I’ve never been convinced that any ORM solves the so-called impedance mismatch problem anyway. And where is the improvement when you still need to know SQL, and now also the entire ORM system and the challenges that come with it? In my experience, these projects typically end up adding redundancy, complexity, and as often as not, some performance issue. Ask your Oracle DBA how he feels about it. 🙂
With SmartClient / SmartGWT, I got complete, declarative control over sensible default SQL generation, with none of those problems and without even requiring a Java model (though mapping is done easily, if and when you actually need it). If you know even a little SQL, you already know enough to be productive with SQLDataSources.
If you’re at all familiar with the SmartClient reference architecture, you should be familiar with the concept of a DataSource. If you’re not familiar with DataSources, chapters 5, 7, and 8 of the Quick Start Guide explain them in-depth. The short version is that a single DataSource provides both client and server with metadata about your data model. On the client, this metadata is used to automate data binding (among other things). On the server, data access (among other things).
I’ll tend to refer to SmartClient documentation most of the time, but the approaches we’ll talk about apply to and are documented in both SmartClient and SmartGWT.
There are a handful of connectors that provide a subset of advanced features out of the box, including one for JPA / Hibernate, but there are good reasons to prefer SQLDataSource if you’re using a relational database to store your data.
Like other tools, you can have database tables created for you if you choose, including audit tables to automatically store changes made by users. The tables included with the sample ‘isomorphic’ database in the SDK are generated tables, and you can use the Admin Console’s Import DataSources feature to generate your own tables from DataSources definitions (.ds.xml files).
The application I was working with for my evaluation used an existing data model. I prefer to write my own DDL so I can control things like indexes and constraints, so I chose to start there. The fastest way to get started with an existing table is to use the DataSource autoDeriveSchema feature. Here’s a DataSource configured for the ‘customers’ table from the Classic Models schema:
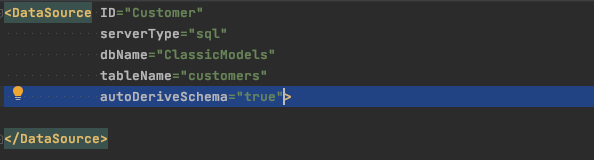
Projects created using a Maven archetype will host the ClassicModels tables in the ClassicModels database, as shown here. SDK examples all use the default ‘isomorphic’ database, so you wouldn’t need the dbName attribute above, but sample DataSources will have names of the form CM_*.ds.xml. E.g., CM_Customer.ds.xml.
At runtime, your database metadata is used to “fill in the blanksâ€. Here, there are no fields so SmartClient will basically build the entire DataSource for you using names, types, lengths, constraints, etc. directly from your table definition.
Assuming your running project is configured to host that sample database, you can use this DataSource right away by loading it and using it in a ListGrid.
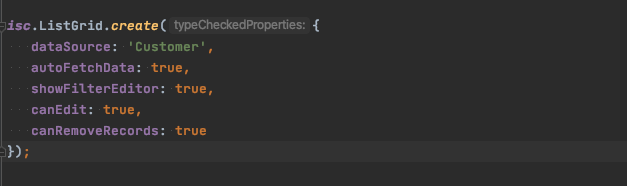
Here we show some SmartClient JavaScript, but the equivalent SmartGWT code looks pretty much the same, except you of course also need a bunch of GWT boilerplate.
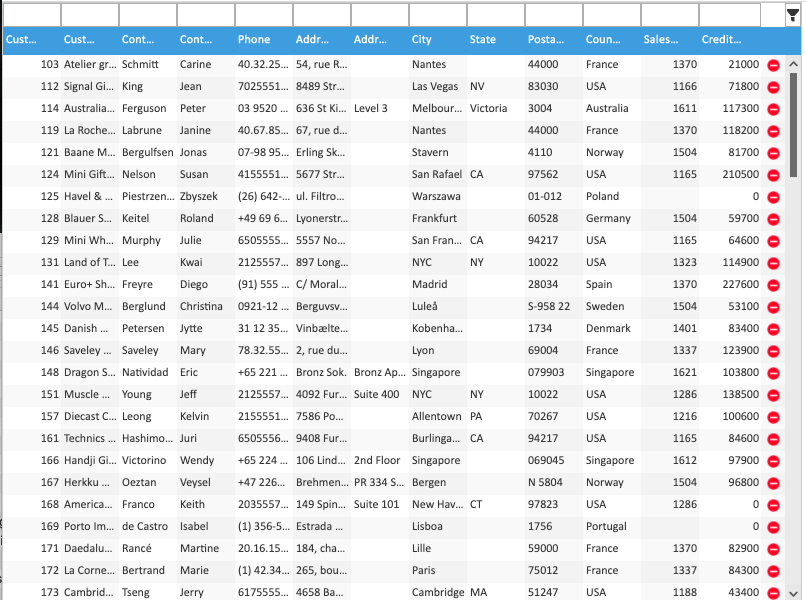
And that’s it. With 12 lines (including formatting) of reusable configuration and code, you have a fully functioning client and server that queries your database for you and lists the result, and the user is able to filter, sort, group, edit, and delete records with validation. This example only shows a grid, but this one-liner DataSource is also ready accept requests from any of SmartGWT’s other databound components, feeding validation errors back to complex forms, providing results for ComboBoxes, or even filter on arbitrary AdvancedCriteria from a FilterBuilder. Bonus, you didn’t have to do anything to protect against SQL injection. In the project I outlined above, I found that I could eliminate a lot of server code, make it more secure, and add significant features while I was at it, with as little as a single line of XML.
Of course there was a lot more to the application than what I’ve demonstrated with the pretend snippet above. You might never need to do anything else to a DataSource like this one, but I was going to have to augment or override at least some of it. You’d want to mark required fields as such, for example. This is easy to do.
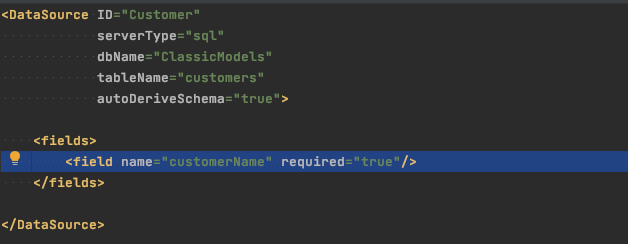
Notice there is no explicit definition for state, postalCode, and so on – these other fields are still derived completely from database metadata. Notice also that we don’t define the customerName field completely either – type, length, etc. are all missing from the explicit definition but autoDeriveSchema continues to fill in the blanks. You can override some or all of that derived metadata selectively too, if you choose. The state column on the database is actually a VARCHAR(50), for example, but you can pretty easily limit input to 2 characters (enforced on both the client and server).

This is all pretty powerful, and the XML definition is in a very accessible format that’s easy for anyone to read and understand. But so far, we’ve been looking at the simplest possible case. What happens when you need to do more?
Here we define an explicit foreignKey attribute (which actually was also present in the derived examples, you just didn’t see it). You can pretty easily add columns from related tables, causing SmartClient to generate a SELECT statement that uses a JOIN to obtain the result. You can influence the way the JOIN is created, and even traverse relationships to retrieve data from a table 2 or more joins away.
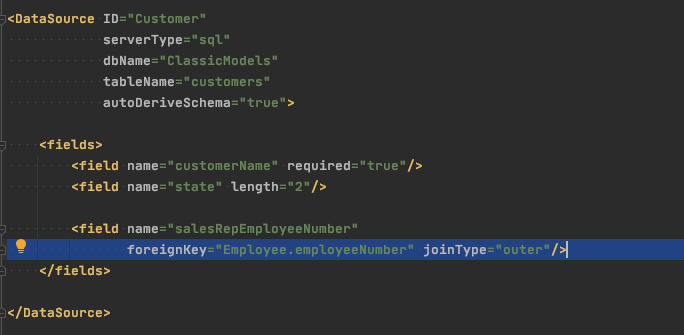
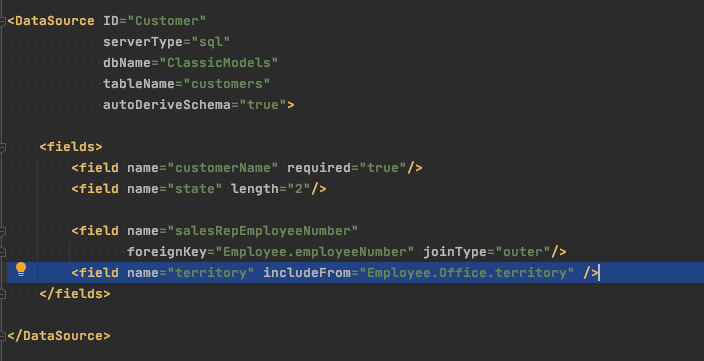
Here we add a territory field and take its value from the Office that the Customer’s salesRep is assigned to, by way of an OUTER JOIN involving 3 tables (Employee and Office definitions not shown for brevity). This “just works” without writing any SQL, or even a single line of Java code to create a statement and execute it. The ListGrid sample code shown above will simply display the data pulled from the related tables, with no change in the client-side code.
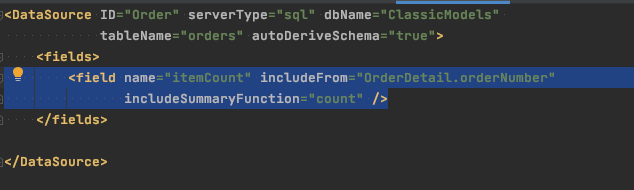
Grouping and aggregations can be handled for you with the same declarative style, or on request if you prefer.
I don’t know of any other platform that does so much for you and reduces complexity at the same time. Think for a minute about everything we’re able to do here, with just a few lines of XML declaration and a tiny block of JavaScript. Play around with your own schemas using a sample project and see for yourself, because we’re only scratching the surface here. Next time, we’ll review some of the very simple techniques that unlock even more power and flexibility.
To be continued in Part 2, here.




